Han Zhou
Hi, I am Han Zhou (pronounced “Hahn Joe”), a fourth-year undergraduate student at HUST.

Research interests: Deep Learning, Computer Vision and Robotics, with an emphasis on Multimodal and Embodied AI.
Email: me at micdz dot cn
Media: GitHub | Bilibili | RedNote
Why I Love AI & Robotics: Gödel, Escher, Bach and Iron Man
Education
2022-2025
B.Eng. in Communication Engineering, Huazhong University of Science and Technology, Wuhan, Hubei, China
2025-2026
Exchange Student, Electrical and Computer Engineering, University of California Santa Barbara, California, USA
Publications
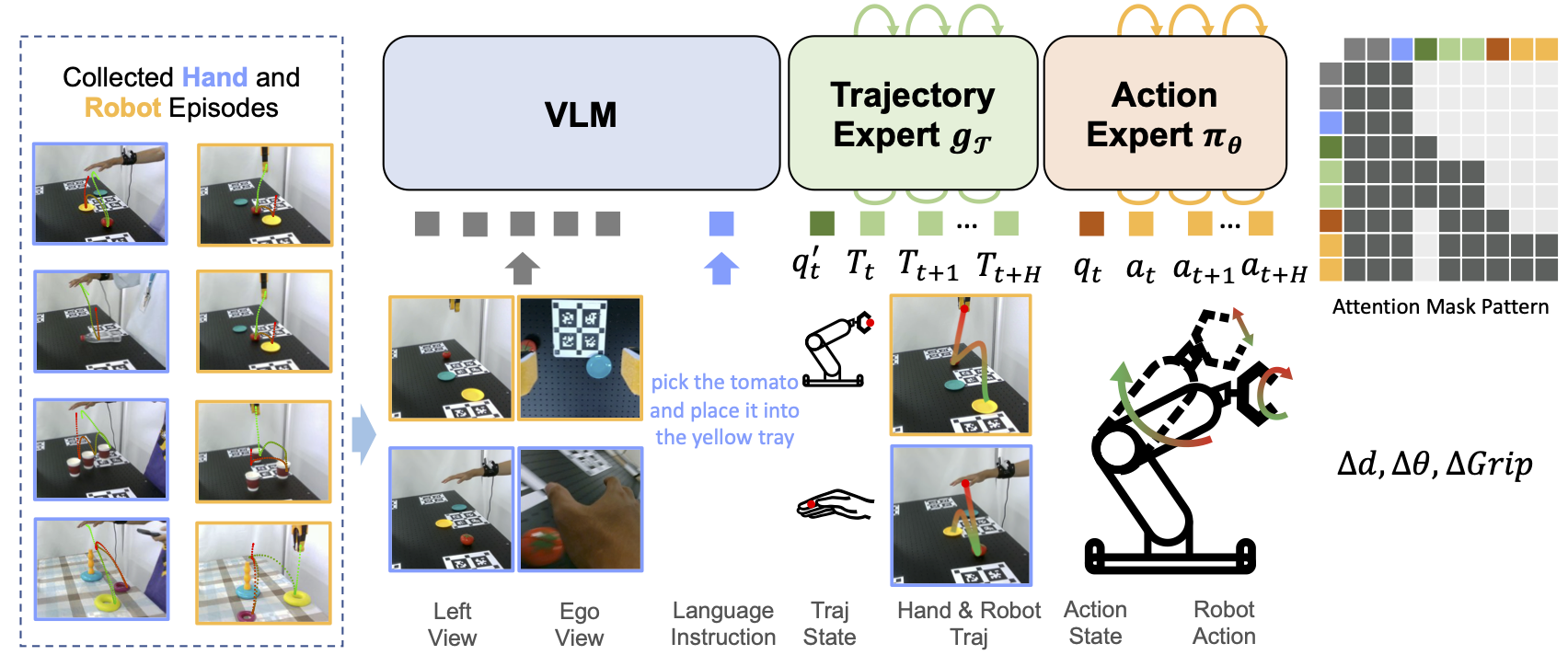
From Human Hands to Robot Arms: Manipulation Skills Transfer via Trajectory Alignment
Preprint ArXiv 2510.00491, Sep. 2025
[Abstract] [GitHub] [arXiv] [Home Page] [Hugging Face]
MANBench: Is Your Multimodal Model Smarter than Human?
ACL'25 Findings, Feb. 2025
[Abstract] [GitHub] [arXiv] [Home Page] [Hugging Face]

Research & Visiting
Medical Image Analysis and Augmented Reality Group, HUST
Jun. 2024 - Feb. 2025, Intern Researcher
Supervised by Prof. Xin Yang
LangYa, RoboMaster Team of HUST
Oct. 2022 - Sep. 2024, Vision Group Member
Supervised by Dr. Yujiang Zeng
Awards
Secured 6 national awards (including 3 first prizes and 1 track championship) in competitions focused on AI/CV, robotics, and embedded systems, earning over CNY 11,000 in prize money.
China College IC Competition
National First Prize, CNY 3,000
Supervised by
Aug. 2025



Global Campus Artificial Intelligence Algorithm Elite Competition
National First Prize, Runner-up
Supervised by
Oct. 2023


Honors
Oct. 2024
National Scholarship for Undergraduate Student | CNY 10,000
Oct. 2024
Outstanding Student Award | CNY 2,000
Blog
Oct. 24, 2025
Guide to Diffusion Denoising Probabilistic Models (DDPM)Aug. 7, 2025
Flow Matching and Diffusion ModelsAll posts
Unless otherwise stated, all content on this blog is licensed under CC BY-NC-SA 4.0 |
RSS subscribe |
Friends
鄂ICP备2025091178号 |
中文