Diffusion Denoising Probabilistic Models (DDPM) have emerged as a powerful class of generative models in machine learning. They have shown remarkable capabilities in generating high-quality images, audio, and other data types. In this guide, we will derive the fundamental concepts behind DDPMs, explain their mathematical foundations, and provide insights into their implementation.
2. Prior Knowledge
2.1. Probabilistic Notations
Before diving into DDPMs, let’s clarify some probabilistic notations that will be used throughout this guide:
p(x): Probability density function (PDF) of a random variable x.
If we want to calculate the probability that x falls within a specific range, we integrate p(x) over that range.
p(x)=N(x;μ,σ2) indicates that X∼p(x) follows a Gaussian distribution with mean μ and variance σ2. The variable before the semicolon is the random variable, and the variables after the semicolon are the parameters of the distribution.
2.2. Bayes’ Theorem
Bayes’ theorem is a fundamental concept in probability theory that relates conditional probabilities. It states that:
If we center our attention on x, we can interpret Bayes’ theorem as follows:
p(x∣y) is the posterior probability of x given y, which represents our updated belief about xafter observing y.
p(y∣x) is the likelihood of observing y given x, which indicates how probable the observation y is for a specific value of x.
p(x) is the prior probability of x, which represents our initial belief about xbefore observing y.
p(y) is the marginal likelihood of y, which serves as a normalizing constant to ensure that the posterior probability sums to 1.
Example:
Suppose there is a rare disease that affects 1% of the population. A diagnostic test for this disease has a 99% accuracy rate, which means if someone has the disease, the test will correctly identify them as positive 99% of the time. While, if someone does not have the disease, the test will incorrectly identify them as positive 2% of the time, calling it a false positive. If a person tests positive, what is the probability that they actually have the disease?
Let D be the event that the person has the disease, and T be the event that the test result is positive. We want to find p(D∣T).
Let’s define the known probabilities:
p(D)=0.01 (prior probability of having the disease)
p(¬D)=0.99 (prior probability of not having the disease)
p(T∣D)=0.99 (likelihood of testing positive given the disease)
p(T∣¬D)=0.02 (likelihood of testing positive given no disease)
Using Bayes’ theorem, we can calculate the posterior probability p(D∣T):
this gives us the total probability of testing positive, considering both cases (having the disease and testing positive, not having the disease and testing positive).
Therefore, if a person tests positive, there is approximately a 33.33% chance that they actually have the disease, despite the high accuracy of the test. This counterintuitive result highlights the importance of considering prior probabilities when interpreting test results.
2.3. Additive Property of Gaussian Distribution
The Gaussian (or normal) distribution is a continuous probability distribution characterized by its mean μ and variance σ2. A key property of Gaussian distributions is that the sum of two independent Gaussian random variables is also a Gaussian random variable. Specifically, if we have two independent Gaussian random variables:
Kullback-Leibler (KL) divergence is a measure of how one probability distribution diverges from a second, expected probability distribution. It is often used in creating a loss function for training probabilistic models, if we want to train a model to approximate a target distribution p(x) with a model distribution q(x), we can minimize the KL divergence from p to q:
The goal of DDPM is to learn a generative model that can produce samples from a target data distribution pdata(z). Here we need to define what is “data” and what is “generation”.
“Data” refers to the real-world samples we want our model to learn from, such as images, audio, or text. These samples are drawn from an unknown distribution pdata(z) that we aim to approximate. What we have access to are finite samples z1,z2,…,zN from this distribution, which we use to train our model.
“Generation” refers to the process of creating plausiblenew samples znew from the learned model. I use the term “plausible” because the generated samples should resemble the real data in terms of structure and characteristics, but they do not need to be exact replicas of any specific training sample. The goal is to capture the underlying distribution of the data so that the model can produce diverse and realistic samples. In the term of mathematics, we want to learn a model distribution pθ(z) that approximates the true data distribution pdata(z), and we can generate new samples znew by sampling from pθ(z), which makes pdata(znew) not too small.
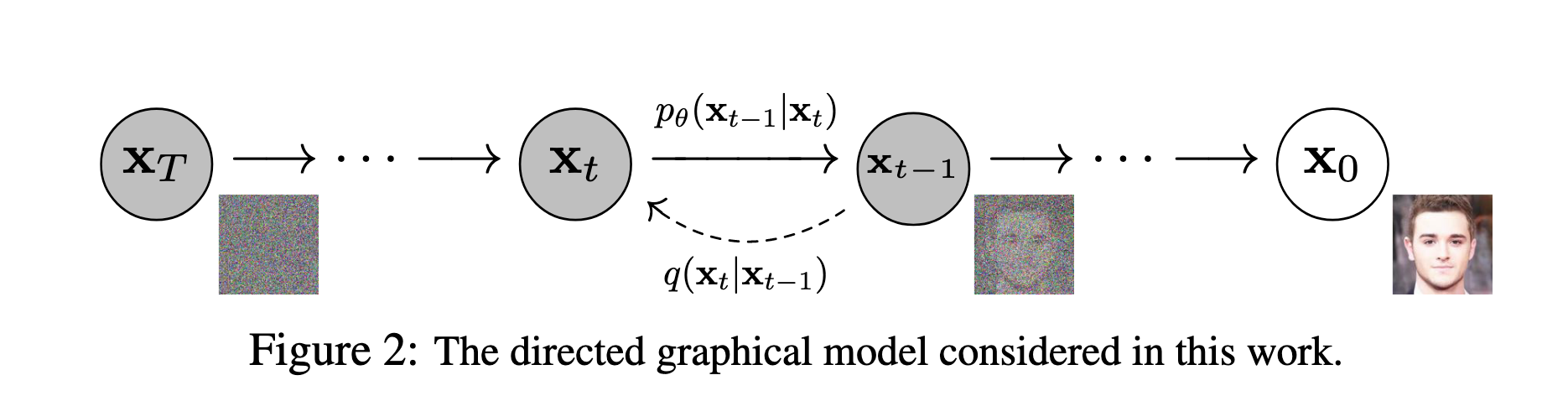
4. Overview of Diffusion Denoising Probabilistic Models (DDPM)
The core idea of DDPM is to model the data generation process as a gradual denoising of a noisy input. The model consists of two main processes: the forward diffusion process and the reverse denoising process.
What the model actually learns is the reverse denoising process, which starts from pure noise and iteratively denoises it to produce a clean sample that resembles the training data. This process is parameterized by a neural network that predicts the noise component at each step, allowing the model to gradually refine the noisy input into a high-quality output.
4.1. Reverse Denoising Process
Let’s denote the clean data sample as x0 and the noisy sample at step t as xt. At the final step T, xT is essentially pure noise p(xT)=N(xT;0,I).
where x0:T denotes the sequence of all latent variables from the initial clean sample to the final noisy sample. This formulation captures the entire generative process, starting from pure noise xT and progressively denoising it to obtain the clean sample x0, using a markovian structure where each step depends only on the previous one.
If we fixed a x0, there may be infinite possible x1:T that can lead to this x0. Therefore, to get the probability of generating x0, we need to marginalize out all possible x1:T:
where μθ(xt,t) and Σθ(xt,t) are the mean and covariance predicted by a neural network parameterized by θ at step t.
4.2. Forward Diffusion Process
The forward diffusion process gradually adds noise to the clean data sample x0 over T steps, resulting in a sequence of noisy samples x1,x2,…,xT. This process is defined as:
Here, βt is a variance schedule that controls the amount of noise added at each step. As t increases, more noise is added, and by the final step T, the sample xT becomes nearly indistinguishable from pure Gaussian noise.
However, for training purposes, we don’t want to sample xt sequentially from x0 to xT, this cost too much time. Fortunately, due to the properties of Gaussian distributions, we can directly sample xt from x0 without going through all intermediate steps.
Proof:
Since each step in the forward diffusion process is Gaussian, the composition of these Gaussian steps results in another Gaussian distribution. As Fomula (29) shows, we can derive the mean and variance of q(xt∣x0) by recursively applying the properties of Gaussian distributions:
To train the DDPM, we need to define a loss function that measures how well the model’s predicted denoising matches the true denoising process. We can use the variational lower bound (VLB) on the negative log-likelihood of the data as our loss function:
However, this expression is still intractable due to the integral over all possible x1:T. To make it tractable, we can decompose the loss into a sum of KL divergences at each time step:
Since each term in the loss function is a KL divergence between two Gaussian distributions, we can use the closed-form solution of KL divergence for Gaussian distributions to compute the loss efficiently during training. This allows us to optimize the model parameters θ using gradient descent, ultimately enabling the DDPM to learn to generate high-quality samples from the target data distribution.
For LT:
Since DDPM fixed the βt schedule, so LT is not relevant to the optimization, we can ignore it during training.
For Lt−1:
To compute Lt−1, we need to determine the posterior distribution q(xt−1∣xt,x0). Using Bayes’ theorem, we have:
Now, we can compute the KL divergence Lt−1 between the posterior distribution q(xt−1∣xt,x0) and the model’s predicted distribution pθ(xt−1∣xt) using the closed-form solution for KL divergence between two Gaussian distributions:
DDPM made a simplification by fixing the covariance Σθ(xt,t) to σt2I, which allows us to ignore the first three terms during optimization because they do not depend on the model parameters θ. Therefore, the loss term Lt−1 simplifies to:
Here we changed the expectation from q to x0 and ϵ, because currently xt is fully determined by x0 and ϵ.
Previously, the q of Eq means for all x1:T follow q(x1:T∣x0), but now we only need to sample x0 from the data distribution and ϵ from the standard normal distribution to compute xt. This significantly simplifies the training process, as we no longer need to sample the entire sequence of noisy samples x1:T.
Now, ϵθ becomes a function approximator that learns to predict the noise ϵ added at each step of the diffusion process from the noisy sample xt.
Because we defined pθ(xt−1∣xt) as a Gaussian distribution N(xt−1;μθ(xt,t),Σθ(xt,t)) in Formula (27), where a made an assumption that the covariance Σθ(xt,t)=σt2I is fixed. Therefore, we can now express the mean μθ in terms of the predicted noise ϵθ: